Tesla Mech Agent
A production-grade, agentic RAG platform.
In a world buzzing with AI demonstrations, moving from a simple chatbot prototype to a robust, production-grade system remains a monumental leap. Many projects showcase impressive capabilities in isolation but fall short when faced with the realities of scalability, reliability, and real-world data. They are demos, not durable systems. Tesla Mech Agent was built to bridge that gap.
🤔 The Problem: Navigating a Maze of Technical Manuals
Finding clear, step-by-step repair information for Tesla vehicles can be a significant challenge. Technicians and enthusiasts often have to sift through dense, lengthy official documentation, trying to piece together the correct procedure. This process is time-consuming, inefficient, and can lead to costly mistakes.
The core issues are:
- Information Overload: The official documentation is vast and not always organized for quick, task-oriented queries.
- Difficult Navigation: Finding the exact section for a specific repair requires knowing the right terminology and navigating a complex structure.
- Lack of Interactivity: Traditional manuals are static. You can’t ask clarifying questions or get interactive guidance.
Tesla Mech Agent was built to solve this exact problem. It provides a simple, chat-based UI that allows users to ask for repair instructions in natural language and receive clear, step-by-step guidance, complete with diagrams and warnings, directly from the source material. It transforms a frustrating search process into a helpful conversation.
🎯 What is Tesla Mech Agent?
This project is a complete, full-stack AI platform that provides a reference architecture for building production-ready Retrieval-Augmented Generation (RAG) systems and intelligent AI agents. It intentionally moves beyond the “toy chatbot” paradigm to tackle the critical engineering challenges of a real-world system: architecture, scalability, observability, and correctness.
The repository serves as:
- A technical portfolio demonstrating production-level ML and AI engineering skills.
- A reference architecture for designing and deploying complex RAG systems.
- A practical guide for implementing best practices in an end-to-end AI project.
🏗️ A Look Inside: System Architecture
The entire platform is designed as a cohesive, end-to-end system that translates a user’s natural language question into a precise, media-rich answer. The architecture is best understood by following the journey of a user’s query from the interface to the final response.
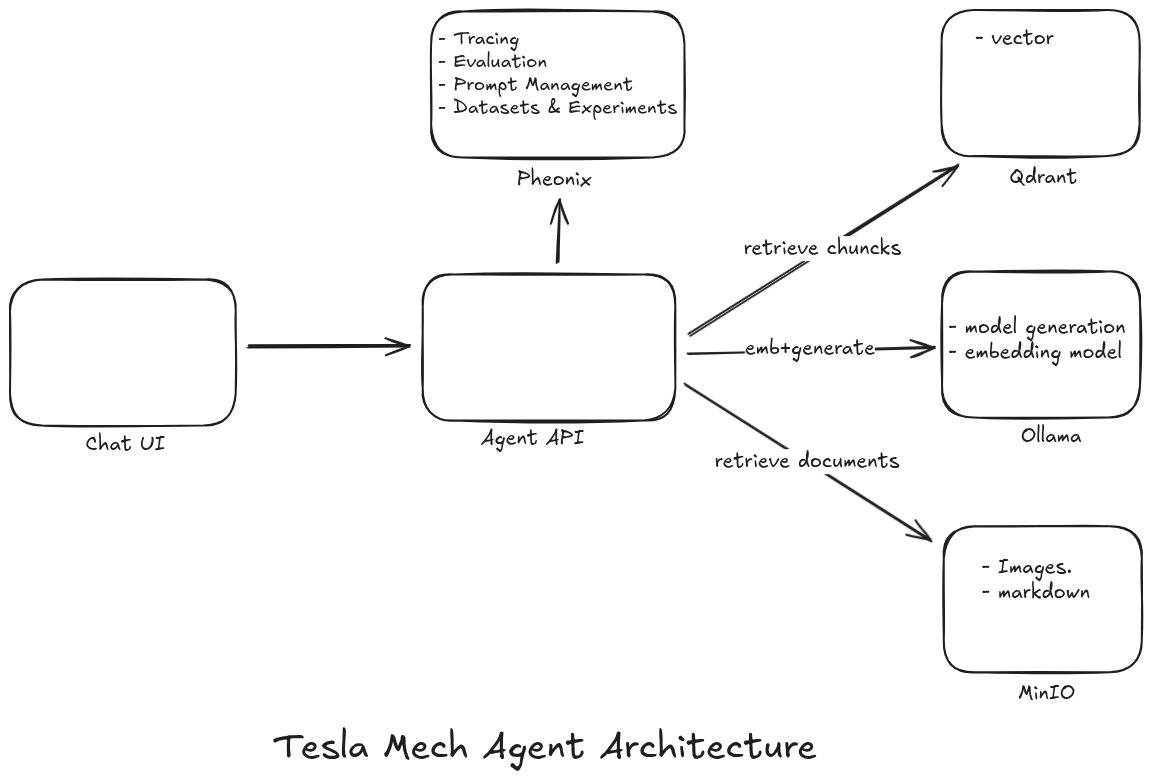 Figure: An overview of the Tesla Mech Agent’s modular and layered architecture, showcasing the interaction between different components from user interface to data storage.
Figure: An overview of the Tesla Mech Agent’s modular and layered architecture, showcasing the interaction between different components from user interface to data storage.
Here’s how it works:
Query & Embedding: The process begins when a user submits a query through the Chat UI. The query is sent to the central Agent API, which uses an embedding model hosted on Ollama to convert the text into a vector representation.
Relevance Analysis & Retrieval: Before proceeding, the agent’s core logic determines if the query is relevant, as detailed in the “Brains” section below. If the query is valid, the agent uses the vector to search for the most relevant document chunks in the Qdrant vector database.
Document & Image Fetching: Once the correct document is identified from the search results, the agent retrieves the full markdown content and any associated images directly from MinIO, our S3-compatible object storage.
Generation & Final Response: With the retrieved context in hand, the agent uses the generation model (also on Ollama) to synthesize a final, grounded answer. This response, complete with formatted text and images from MinIO, is then sent back to the user in the Chat UI.
Throughout this process, the entire flow is monitored by Pheonix for tracing, evaluation, and observability, ensuring the system remains reliable and performant. This modular, service-oriented design allows each component to be scaled and maintained independently, creating a truly production-grade RAG platform.
🧠 Guiding Principles: Core Design Philosophy
This project wasn’t just built to work; it was built to last. The entire system is founded on a set of core principles that reflect modern, production-grade software engineering.
- Separation of Concerns: Data ingestion, embedding, retrieval, agent logic, and UI are all isolated, independent services.
- Typed, Config-Driven Pipelines: Using YAML and Pydantic, the entire system is configured, not hardcoded, for maximum flexibility.
- Observability-First: With built-in tracing, metrics, and evaluation, we treat observability as a core feature, not an afterthought.
- Deterministic & Safe RAG: We enforce strict relevance grading and controlled context to eliminate hallucinations and build trust.
- Scalable by Construction: The system is designed from the ground up to be scalable, using async pipelines, batch processing, and containerized services.
🤖 The Brains: AI Agent Control Flow
The heart of the platform is a deterministic, decision-driven agent implemented with LangGraph. This graph-based approach ensures that the agent’s behavior is predictable, traceable, and easy to debug—critical features for any production system.
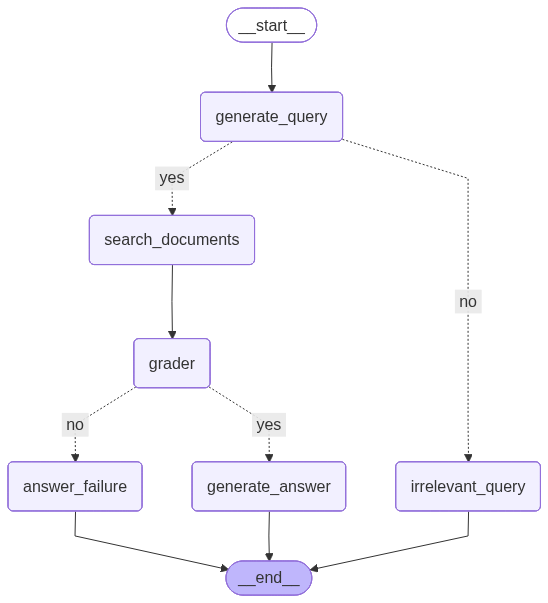
How It Works: A Step-by-Step Flow
The agent follows a clear, multi-step process to handle user requests, from initial query analysis to final, grounded answer generation.
generate_query: An LLM analyzes the user’s input, validates if it’s a relevant query, and rewrites it for optimal retrieval.search_documents: Performs efficient semantic retrieval from a Qdrant vector store to find the most relevant information.Grading Decision: A conditional LLM “grader” checks if the retrieved documents are sufficient to answer the query. This is a critical quality gate.generate_answer: If the documents pass the grade, this node generates a final answer, strictly grounded in the retrieved context.answer_failure/irrelevant_query: If a query is invalid or the information is insufficient, the agent routes to a safe exit path, informing the user clearly without fabricating information.
🧪 Proving its Mettle: Evaluation & Training
A production system requires a commitment to quality and continuous improvement.
Retrieval Evaluation
The project includes a full evaluation framework to objectively measure the performance of the retrieval stack, with metrics like Recall@K, Precision@K, and NDCG@K. This allows for data-driven comparisons between different embedding models, retrieval strategies, and RAG pipelines.
Model Fine-Tuning
The stack includes a complete workflow for contrastive fine-tuning of embedding models, mirroring real industrial practices. This covers everything from hard negative mining and custom dataset abstractions to publishing models on the Hugging Face Hub.
🧰 Tech Stack
Core Technologies
- Languages: Python 3.11+
- API: FastAPI
- ML / AI: PyTorch, Sentence Transformers, Hugging Face, vLLM
- Retrieval: Qdrant
- Data: Polars, Pandas, MinIO (S3-compatible)
- Agent & UI: Ollama, LangChain, LangGraph, Chainlit
- Infrastructure: Docker & Docker Compose, GPU acceleration, Kubernetes
📝 Recap: Key Takeaways
Tesla Mech Agent stands as a robust demonstration of a production-ready RAG platform. Key takeaways include:
- Bridging the Gap: Moves beyond prototypes to tackle real-world scalability, reliability, and observability challenges.
- Problem-Solving: Specifically designed to simplify navigation through complex technical manuals for Tesla vehicle repairs.
- Comprehensive Architecture: Features a modular, scalable system with distinct Data, ML/Embedding, AI Agent, and User Interface layers.
- Guiding Principles: Built on strong software engineering foundations like Separation of Concerns, Observability-First, and Deterministic RAG.
- LangGraph Powered: Utilizes LangGraph for a predictable and traceable AI agent control flow, ensuring grounded answer generation.
- Evaluated & Tuned: Incorporates evaluation frameworks for retrieval performance and workflows for embedding model fine-tuning.
📌 Disclaimer
This project is built for educational and portfolio purposes. It demonstrates engineering patterns and system design, not proprietary Tesla data or workflows.
🙌 Authors
Built with care by Jalal Khaldi & KARIM ZAGHLAOUI ML Engineers · AI Systems · Retrieval & Agents