Knowledge Search Agent
A production-grade, academic RAG platform for scientific research.
In a world buzzing with AI demonstrations, moving from a simple chatbot prototype to a robust, production-grade system remains a monumental leap. Many projects showcase impressive capabilities in isolation but fall short when faced with the realities of scalability, reliability, and real-world data. They are demos, not durable systems. Knowledge Search Agent was built to bridge that gap.
🤔 The Problem: Navigating the Sea of Scientific Research
Finding precise information within large-scale scientific corpora, such as the thousands of papers on arXiv, is a significant challenge. Researchers and engineers often spend hours sifting through dense, technical documentation to find specific methodologies or results. This process is time-consuming and often misses critical, contextually relevant information.
The core issues are:
- Information Overload: The volume of academic papers is vast and not organized for quick, task-oriented queries.
- Semantic Gap: Traditional search misses conceptually related information when exact keywords aren’t used.
- Lack of Reliability: Many RAG “demos” suffer from hallucinations, making them untrustworthy for scientific applications.
Knowledge Search Agent was built to solve these exact problems. It provides a production-grade interface that allows users to ask complex questions and receive clear, grounded answers directly from the source material. It transforms a frustrating search process into a reliable, scientific conversation.
🎯 What is Knowledge Search Agent?
This project is a complete, full-stack AI platform designed to demonstrate how to build production-ready Retrieval-Augmented Generation (RAG) systems and academic AI agents. It focuses on the Artificial Intelligence (AI) category of arXiv, covering machine learning, neural networks, reinforcement learning, and theoretical AI.
The repository serves as:
- A technical portfolio for ML, AI, and Platform engineering roles.
- A reference architecture for academic RAG systems.
- A proof of production-level engineering skills, focusing on architecture, scalability, and observability.
🏗️ A Look Inside: System Architecture
The platform is designed as a cohesive, end-to-end system that translates a user’s natural language question into a precise, scientifically grounded answer.
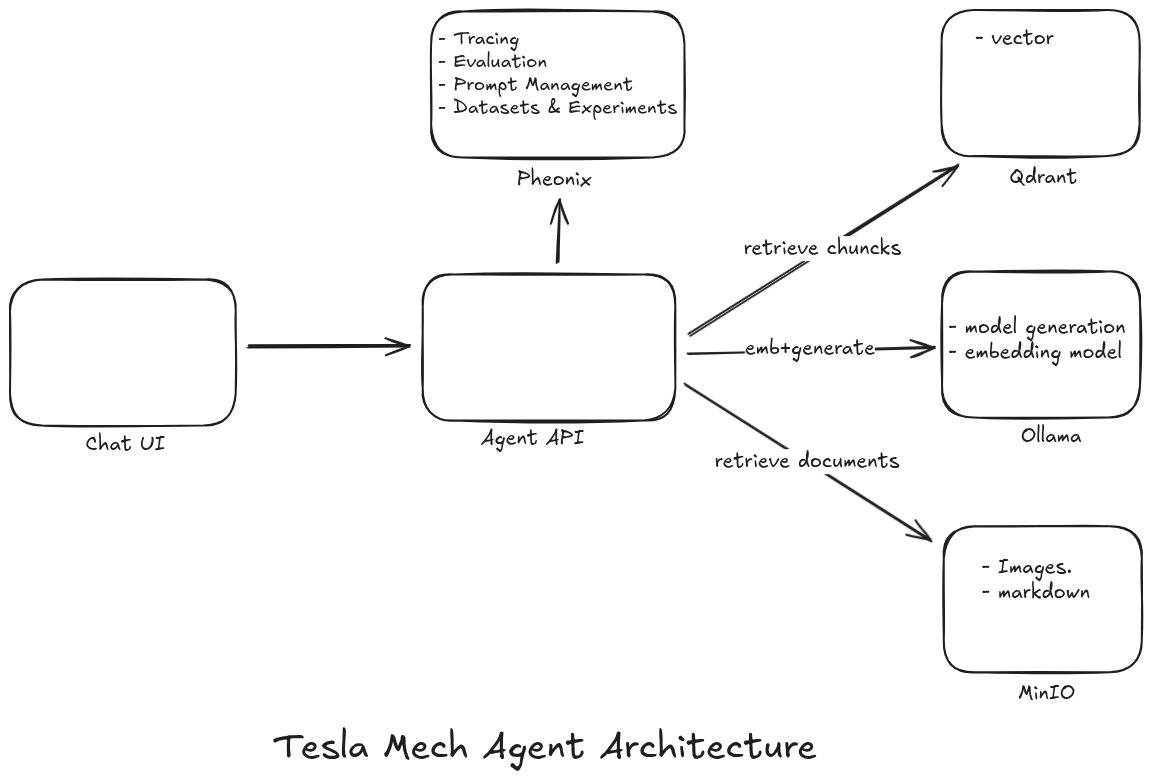 Figure: The modular and layered architecture of the Knowledge Search Agent, showcasing the interaction between data, embedding, and agent layers.
Figure: The modular and layered architecture of the Knowledge Search Agent, showcasing the interaction between data, embedding, and agent layers.
Detailed Layered Approach
- Data Layer: Efficient ingestion of raw research papers into storage (MinIO).
- ML / Embedding Layer: Transforming text into high-dimensional vectors for semantic search.
- AI Agent Layer: Advanced orchestration using LangGraph for deterministic reasoning.
- User Interface Layer: A responsive streaming chat UI for interactive research.
🧠 Guiding Principles: Core Design Philosophy
This project wasn’t just built to work; it was built to last. The entire system is founded on a set of core principles:
- Separation of Concerns: Data ingestion, embedding, retrieval, agent logic, and UI are isolated services.
- Typed, Config-Driven Pipelines: YAML + Pydantic-based configuration for maximum flexibility and reliability.
- Observability-First: Tracing, metrics, and evaluation are treated as first-class citizens (using Phoenix).
- Deterministic & Safe RAG: Strict relevance grading and controlled context usage to eliminate hallucinations.
- Scalable by Construction: Async pipelines, batch processing, and containerized services.
🤖 The Brains: AI Agent Control Flow
Knowledge Search Agent features two distinct agent architectures implemented with LangGraph, providing a balance between speed and safety.
⚡ Fast Mode (Low-Latency RAG)
Designed for rapid research exploration and interactive usage. It focuses on query normalization, tool-driven retrieval, and immediate answer generation.
🛡️ Safe Mode (Deterministic + Graded RAG)
Designed for high academic reliability where zero hallucination tolerance is required. It adds a Critical Safety Node (Grader) that verifies if retrieved passages truly answer the query before generating a response.
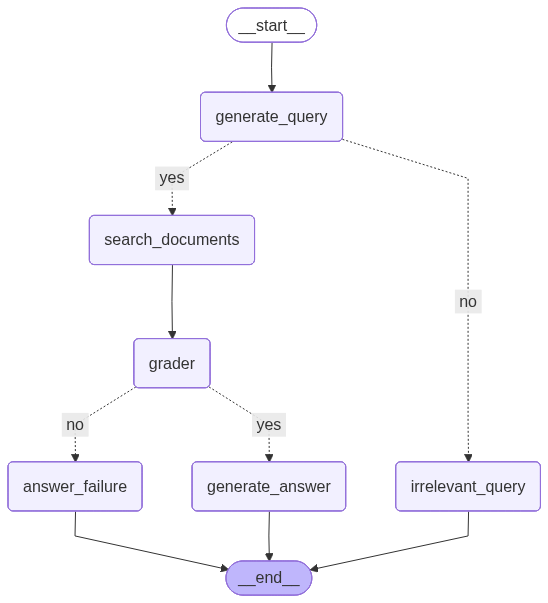 Figure: The agent’s control flow, visualized as a state machine that handles query generation, document search, and response grading.
Figure: The agent’s control flow, visualized as a state machine that handles query generation, document search, and response grading.
🧪 Proving its Mettle: Evaluation & Training
A production system requires a commitment to quality and continuous improvement.
Retrieval Evaluation
The project includes a full evaluation framework measuring metrics like Recall@K, Precision@K, MRR@K, and NDCG@K. This allows for data-driven comparisons between different embedding models and retrieval strategies.
Model Fine-Tuning
The stack mirrors real industrial workflows with support for contrastive training, hard negative mining, and custom dataset abstractions, with models published to the Hugging Face Hub.
🧰 Tech Stack
Core Technologies
- Languages: Python 3.11+
- ML / AI: PyTorch, Sentence Transformers, Hugging Face, vLLM
- Retrieval: Qdrant (Vector DB)
- Data: Polars, Pandas, MinIO (S3-compatible)
- Agent & UI: LangChain, LangGraph, FastMCP, Streaming Chat UI
- Infrastructure: Docker & Docker Compose, GPU acceleration, Phoenix (Observability)
📝 Recap: Key Takeaways
Knowledge Search Agent stands as a robust demonstration of a production-ready RAG platform. Key takeaways include:
- Bridging the Gap: Moves beyond prototypes to tackle real-world scalability, reliability, and observability.
- Academic Focus: Specifically designed for navigating large-scale scientific corpora with high precision.
- Modular Architecture: Isolated layers for data, embeddings, agents, and UI ensure long-term maintainability.
- Safety-First: Dual-mode agent architecture allows for flexible tradeoffs between latency and deterministic correctness.
- Evaluation-Driven: Full metrics and fine-tuning pipelines ensure continuous improvement based on empirical data.
📌 Disclaimer
This project is built for educational and portfolio purposes. It demonstrates engineering patterns and system design using publicly available arXiv papers (cs.AI category). It does not claim ownership of scientific content.
🙌 Authors
Built with care by Jalal Khaldi & KARIM ZAGHLAOUI ML Engineers · AI Systems · Retrieval & Agents